2024.10.14 - [분류 전체보기] - [빅데이터분석 | Numpy] 2. 특수 배열 : zeros, empty, eye, linspace
[빅데이터분석 | Numpy] 2. 특수 배열 : zeros, empty, eye, linspace
2024.10.03 - [빅데이터분석] - [빅데이터분석 | Numpy] 1. Numpy 란?, np.array [빅데이터분석 | Numpy] 1. Numpy 란?, np.array본 글은 대학교 강의를 듣고 공부한 내용을 정리한 글로 틀린 내용이 있을 수 있습니
sua0105.tistory.com
이전에는 몇 가지 특수한 행렬을 만들어봤다.
이번에는 numpy의 중요한 함수인 reshape과 darray 등과 같은 새로운 개념들을 배워보자
1. reshape : numpy.reshape(a, newshape, order='C'), a.reshape(newshape, order = 'C')
reshape 함수를 사용하는 방법에는 2가지가 있다.
- a : 원본 행렬
- newshape : 변경할 행렬
- order : 배열의 요소 재배열 방식, 기본 값은 'C' (행 우선 순서)
- 이를 활용해서 1차원 배열을 2차원 배열로 재배열 해보자
arr = np.array([1,2,3,4,5,6])
print(arr)
arr1 = arr.reshape((2,3))
print(arr1)
arr2 = np.reshape(arr, (3,2))
print(arr2)
여기서 C우선과 F 우선이 뭘까?
- 행 우선 순서와 열 우선 순서의 차이점이 무엇일까?
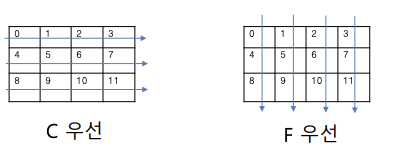

행 우선 과 열 우선의 개념을 그림으로 표현한 것이다. 햇갈리니 한 번 직접 확인해 보자
arr = np.array([1,2,3,4,5,6])
print(arr)
arr1 = arr.reshape((2,3),order ='C')
print(arr1)
arr2 = np.reshape(arr, (2,3), order = 'F')
print(arr2)
앞선 코드를 재작성하면 다음과 같은 결과를 확인 할 수 있다.
명확한 차이가 보이는데
'C' : 행 우선은
1,2,3 -> 4,5,6 1행 2행 순서대로 요소가 채워진다.
'F' : 열 우선은
1,2 -> 3,4-> 5,6 1열 2열 3열 순서대로 요소가 채워진다.
- -1을 활용해서 행렬을 재배열 할 수 있다.
arr = np.array([1,2,3,4,5,6])
print(arr)
arr1 = arr.reshape((2,-1))
print(arr1)
arr2 = arr.reshape(-1)
print(arr2)
arr3 = arr.reshape(-1,1)
print(arr3)
- (n,-1), (-1,n) 하면 n에 맞춰서 자동으로 차원을 재정렬해준다.
- reshape(-1)하면 평탄화 하여 1차원의 배열을 만들어준다.
- reshape(1,-1) 하면 6행 1열의 2차원의 행열을 만들어준다.
reshape(-1)하여 나오는 결과도 결국 (1,6)의 1차원 배열 아닌가??
print(arr2.shape)
print(arr3.shape)
모양을 확인해보자 arr2 는 (6,)의 1차원, arr3은 (6,1)의 2차원 임을 확인할 수 있다.
- 3차원의 배열을 reshape 해보자
arr = np.arange(24)
print(arr)
arr1 = arr.reshape(2,3,4)
print(arr1)
arr2 = np.arange(24).reshape(2,3,4)
print(arr2)
코드를 살펴보자
우선 np.arrange를 사용하여 기본 행렬을 만들어줬다.
numpy.arange([start, ]stop, [step, ]dtype=None) : 연속적인 숫자 범위를 생성하는 함수
- start, step, dtype는 선택사항
- reshape를 통해 (depth, row, column)을 입력하여 주면 3차원의 행렬이 완성된다.
- 마지막 줄과 같이 한 줄에 행렬을 생성하고 reshape도 가능하다
ndarray는 무슨 속성들을 가지고 있을까?
ndarray를 탐색할 때 다음과 같은 속성들을 살펴볼 수 있다.
print(arr2.ndim)
print(arr2.shape)
print(arr2.size)
print(arr2.dtype)
print(arr2.itemsize)
print(arr2.strides)
위에서 만든 arr2 행렬을 살펴보았다.
- ndim : 행렬의 차원
- shape : 모양
- size : 원소의 수
- dtype : 데이터 타입
- itemsize : 메모리 크기 ( int 는 64비트를 사용하므로 -> 8바이트)
- strides : 각 차원에서 다음 요소로 넘어가기 위해 건너뛰어야 하는 바이트 수
구조화된 데이터 타입을 사용하고 싶다면? -> 복잡한 데이터를 배열로 다룰 수 있다
#단일 데이터 타입 정의
print(np.dtype(np.int16))
#구조화된 데이터 타입 정의 -> 배열의 각 요소가 여러 필드를 가질 수 있다.
print(np.dtype([('f1', np.int16)]))
#필드 'f1'과 그 데이터 타입을 지정
print(np.dtype([('f1', [('f1', np.int16)])]))#f1이라는 상위 필드 속 f1이 또 있는 것int16
[('f1', '<i2')]
[('f1', [('f1', '<i2')])]
- <i2 : < 는 작은 엔디안으로 컴퓨터가 데이터를 메모리에 저장하는 방식을 나타낸다.
- i2는 2바이트의 int형이라는 뜻
더 자세한 예를 들어보자
#데이터타입 3가지를 지정
#단일 데이터
dt_1 = np.dtype(np.int16)
#두가지 필드를 가지는 데이터 구조
dt_2 = np.dtype([('f1',np.int16),('f2',np.int16)])
# 두 개의 필드를 가지는 데이터 구조
dt_3 = np.dtype([('a','f8'),('b','S10')])
arr1= np.zeros(5,dtype =dt_2)
print(arr)
print(arr.dtype)
arr2= np.zeros(5,dtype =dt_3)
print(arr2)
print(arr2.dtype)

3가지 데이터타입을 주어주었을 때, np.zeros(5)의 출력 예시를 확인해 보았다.
- dt_2처럼 두 개의 필드를 가지고 있고, 그 필드의 값이 int일때는 (0,0)이 5개 출력된다.
- dt_3은 두 개의 필드를 가지고 있고, 한 개는 float, 한 개는 최대 10바이트의 문자열이다.
이 경우 (0.0, 과 b' ') 튜플이 5개 출력된다. b ' ' 에서의 b는 바이트 문자열임을 알려주는 표시이다.
더 다양한 활용 예시를 봐보자
dt = np.dtype('i4, (2,3)f8')
arr = np.zeros(2, dtype = dt)
arr[0][0] = 10
arr[0][1] = np.array([[1,2,3],[4,5,6]])
arr[1][0] = 20
arr[1][1] = np.array([[1.5,2.5,3.5],[4.5,5.5,6.5]])
print(arr)
이번엔 첫번째 필드는 정수, 두번째 필드는 실수로 구성된 (2,3)의 2차원 행렬로 구성된 데이터 타입을 다뤄보자.
- np.zeros를 통해 0으로 초기화된 행렬을 만든다
- arr[0][0]은 arr의 첫번째 원소의 첫 번째 필드에 접근하는 것이다.
- arr[0][1]은 첫번째 요소의 두 번째 필드에 접근
따라서 다음과 같이 데이터를 넣을 수 있다.
dt = np.dtype({'surname' : ('S25',0),'age' : (np.uint8,25)})
arr = np.array([('Smith',30),('Joon',38)], dtype = dt)
print(arr)
print(arr['surname'])
print(arr['age'])
이번 데이터 타입은 'surname'과 'age'라는 필드로 나뉜다.
- surname필드는 최대 25바이트의 문자열이며, 0 바이트 오프셋에서 시작한다.
- age 필드는 최대 8바이트의 부호 없는 정수이며, 25바이트 오프셋에서 시작한다.
- surname과 age 필드 각각 출력이 가능하다
여기서 오프셋이란?
메모리에서 데이터가 시작하는 위치를 지정하는 값으로 데이터가 저장되는 메모리 상의 기준 위치에서부터 얼마나 떨어져 있는지를 나타내는 숫자이다.
- 구조화된 데이터 타입을 정의할 때, 각 필드가 메모리에서 어디에 위치할지를 오프셋을 사용해 지정할 수 있으며, 이 기능을 통해 서로 다른 데이터 타입을 가진 필드를 고정된 위치에 저장하고, 빠르게 접근할 수 있다.

